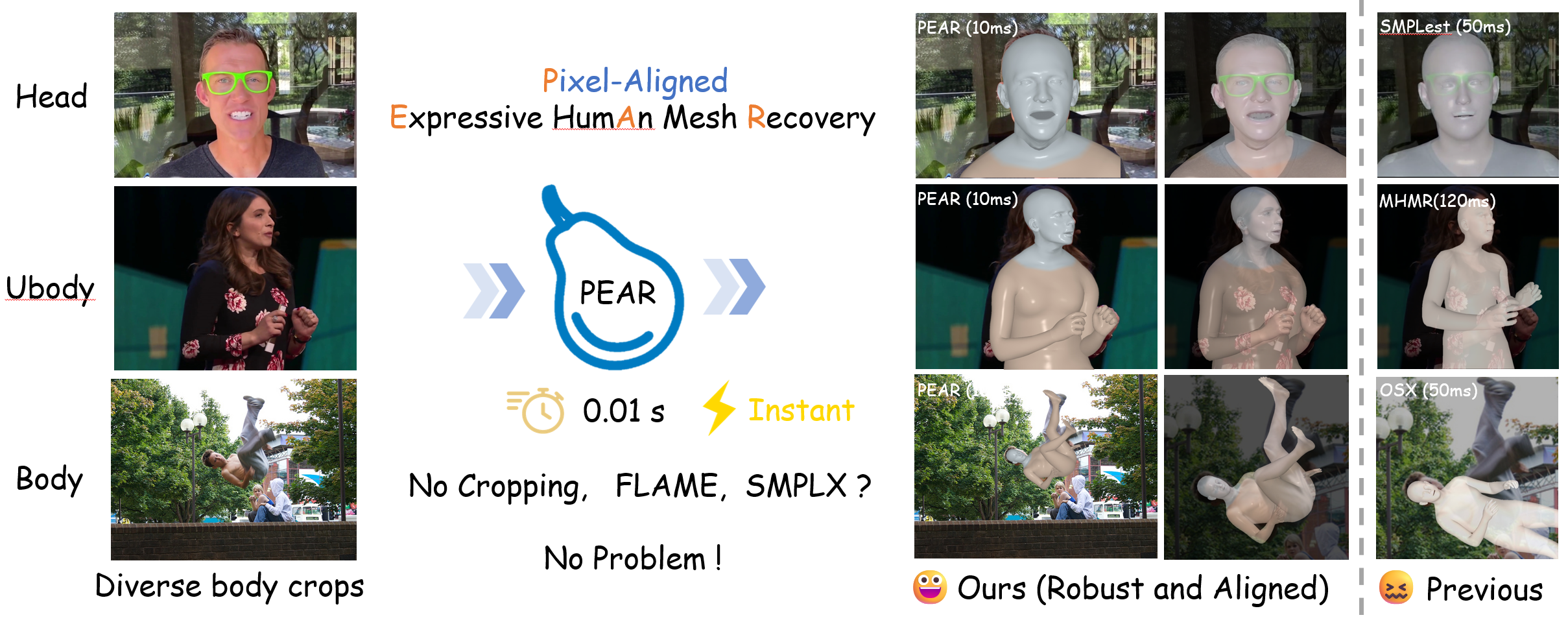
PEAR: Pixel-aligned Expressive humAn mesh Recovery
Pixel-aligned expressive human mesh recovery for high-fidelity dynamic human reconstruction.
I am a Senior Researcher working on human-centric generation, digital humans, and embodied intelligence at
International Digital Economy Academy (IDEA).
My work builds controllable and high-fidelity systems for human content generation, reconstruction, motion, and embodied applications.
Before joining IDEA, I worked at Tencent ARC Lab and received my bachelor's and master's degrees from
South China University of Technology, advised by
Prof. Yuhui Quan and
Prof. Yong Xu.
[2025.07] CanonSwap was accepted to ICCV 2025.
[2023.04] Joined IDEA as a Senior Researcher.
[2022.12] HWFI was published in IJCV 2022.
[2023.04 - Present] Senior Researcher at International Digital Economy Academy (IDEA).
[2021.07 - 2023.04] Researcher at Tencent ARC Lab.
[2020.04 - 2021.06] Research Intern at Tencent ARC Lab.
Representative works across human-centric generation, digital humans, and embodied intelligence.
* equal contribution, # corresponding author
PEAR: Pixel-aligned Expressive humAn mesh Recovery
Pixel-aligned expressive human mesh recovery for high-fidelity dynamic human reconstruction.

Qffusion: Controllable Portrait Video Editing via Quadrant-Grid Attention Learning
Controllable portrait video editing with quadrant-grid attention for precise semantic manipulation.
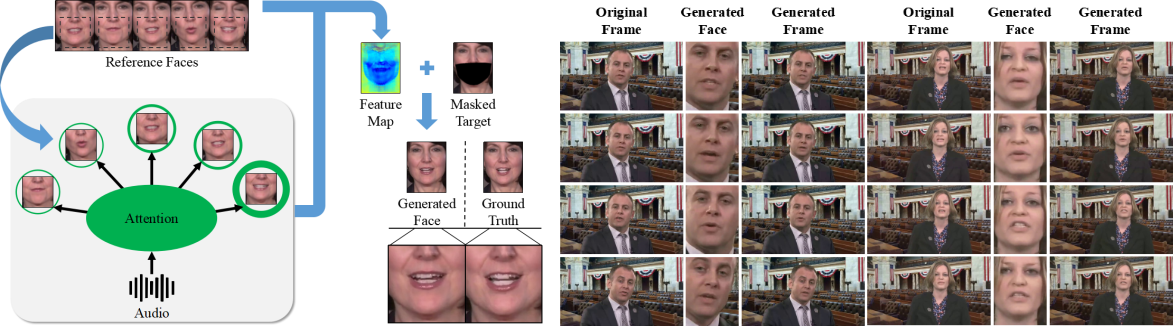
Identity-Preserving Video Dubbing Using Motion Warping
Identity-preserving video dubbing with motion warping for expressive and temporally consistent speech transfer.
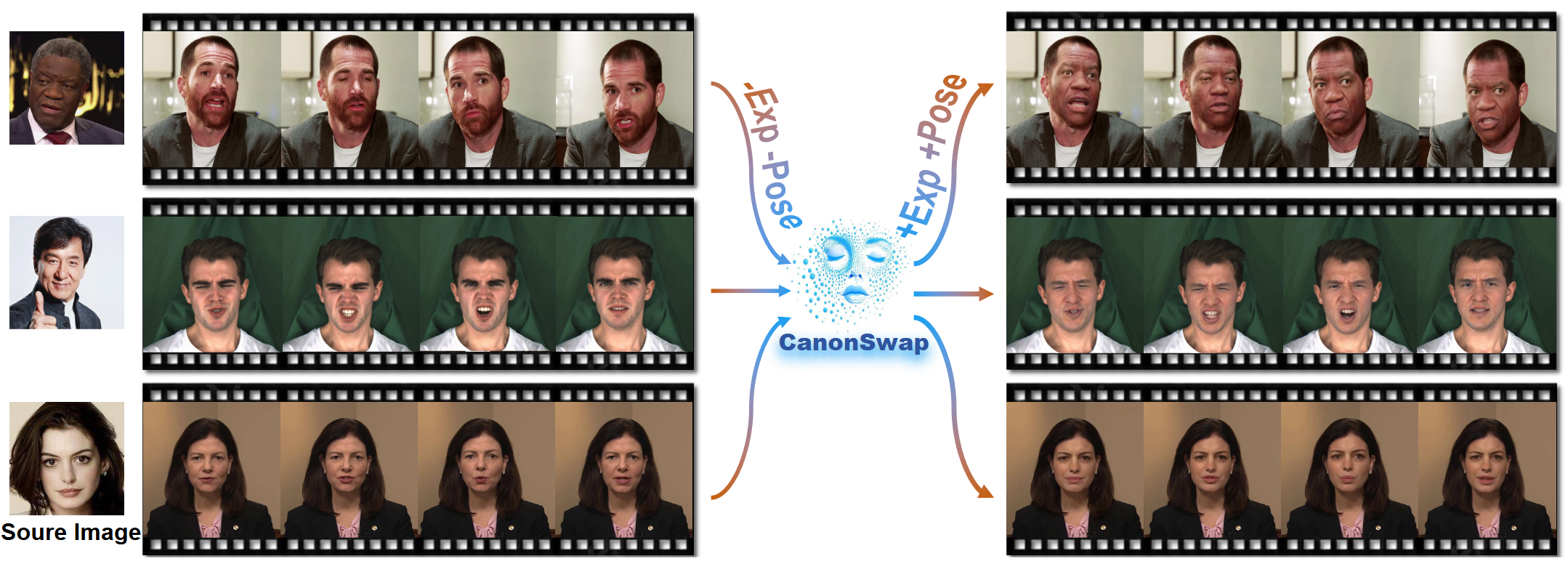
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Canonical-space modulation for high-fidelity and temporally consistent video face swapping.
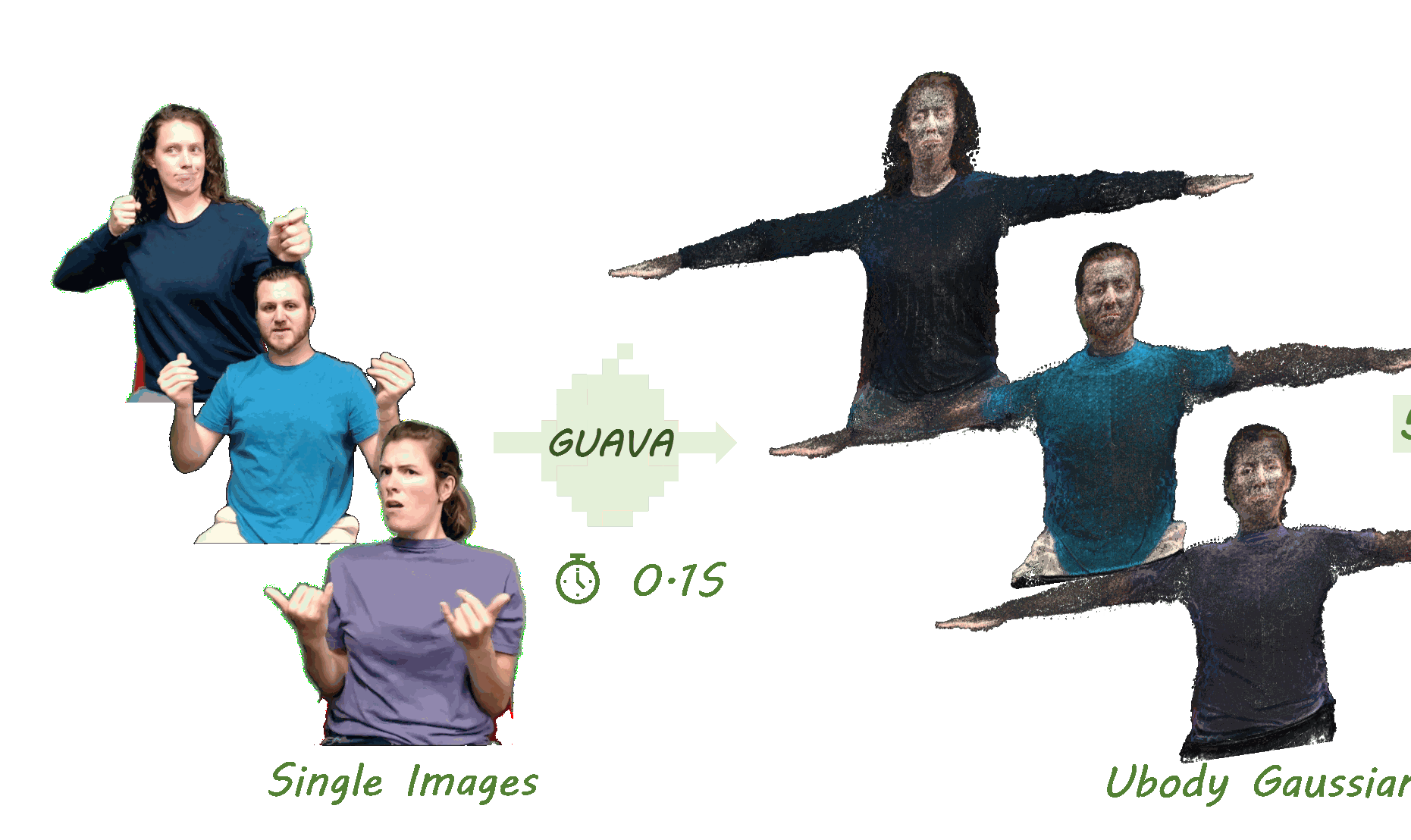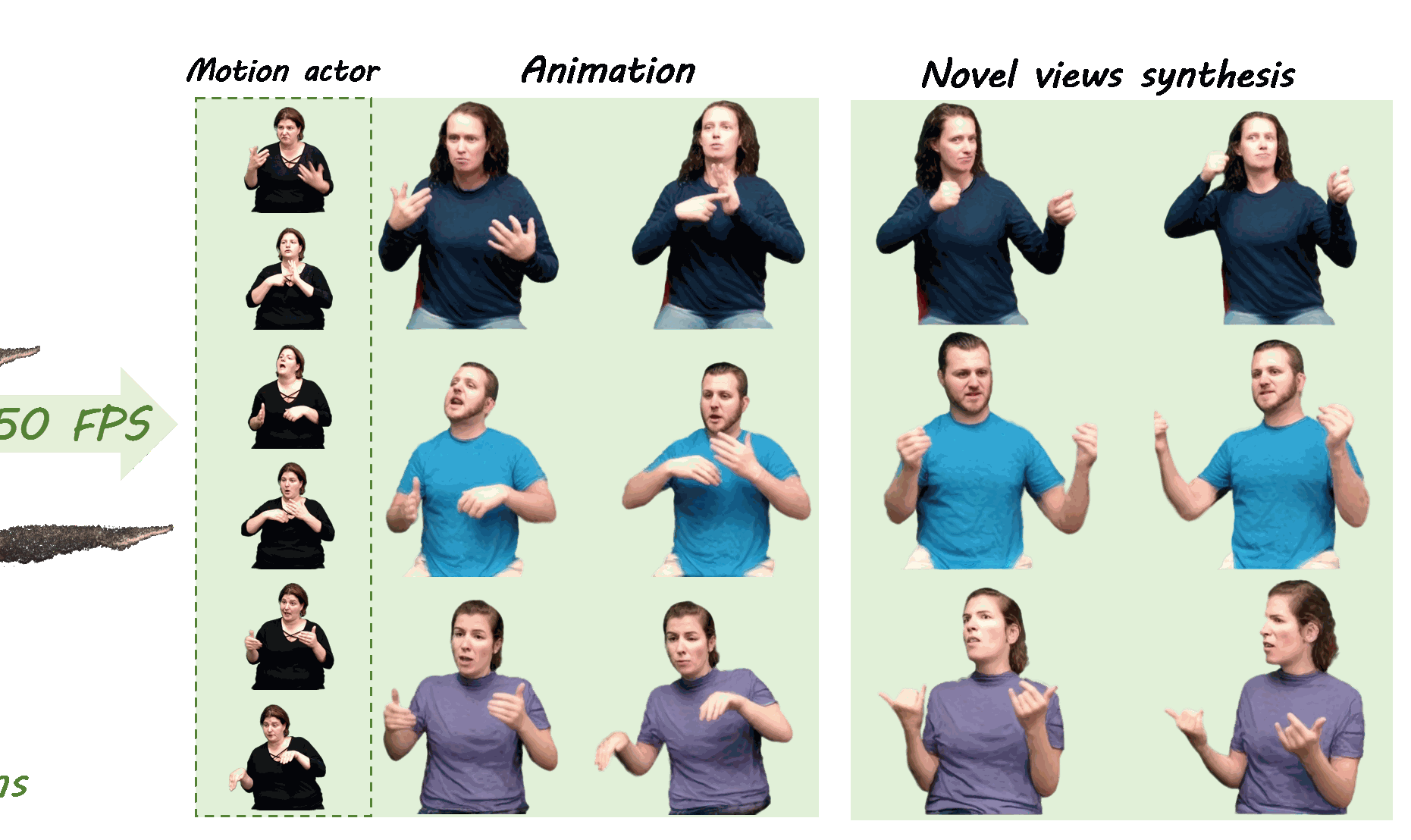
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
A generalizable 3D Gaussian avatar framework for upper-body human reconstruction and animation.
HRAvatar: High-Quality and Relightable Gaussian Head Avatar
A relightable Gaussian head avatar method for high-quality dynamic portrait reconstruction.

TEASER: Token Enhanced Spatial Modeling for Expressions Reconstruction
Token-enhanced spatial modeling for detailed and robust expression reconstruction.
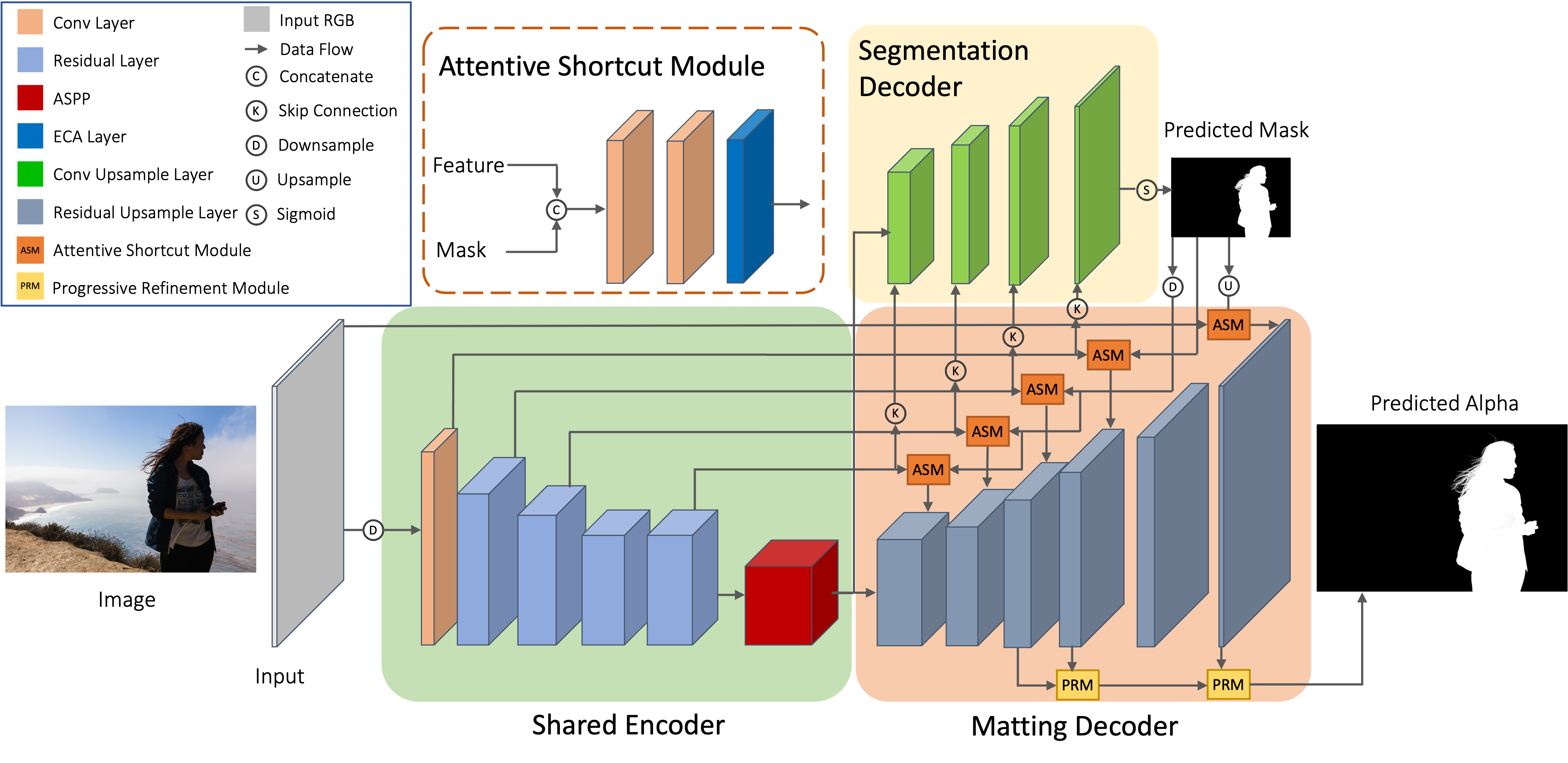
Robust Human Matting via Semantic Guidance
Semantic guidance improves robustness in challenging human matting scenarios.

Composite photograph harmonization with complete background cues
Background-aware harmonization for realistic composite photograph editing.

HWFI: Hybrid Warping Fusion for Video Frame Interpolation
Hybrid warping fusion for accurate and temporally coherent video frame interpolation.
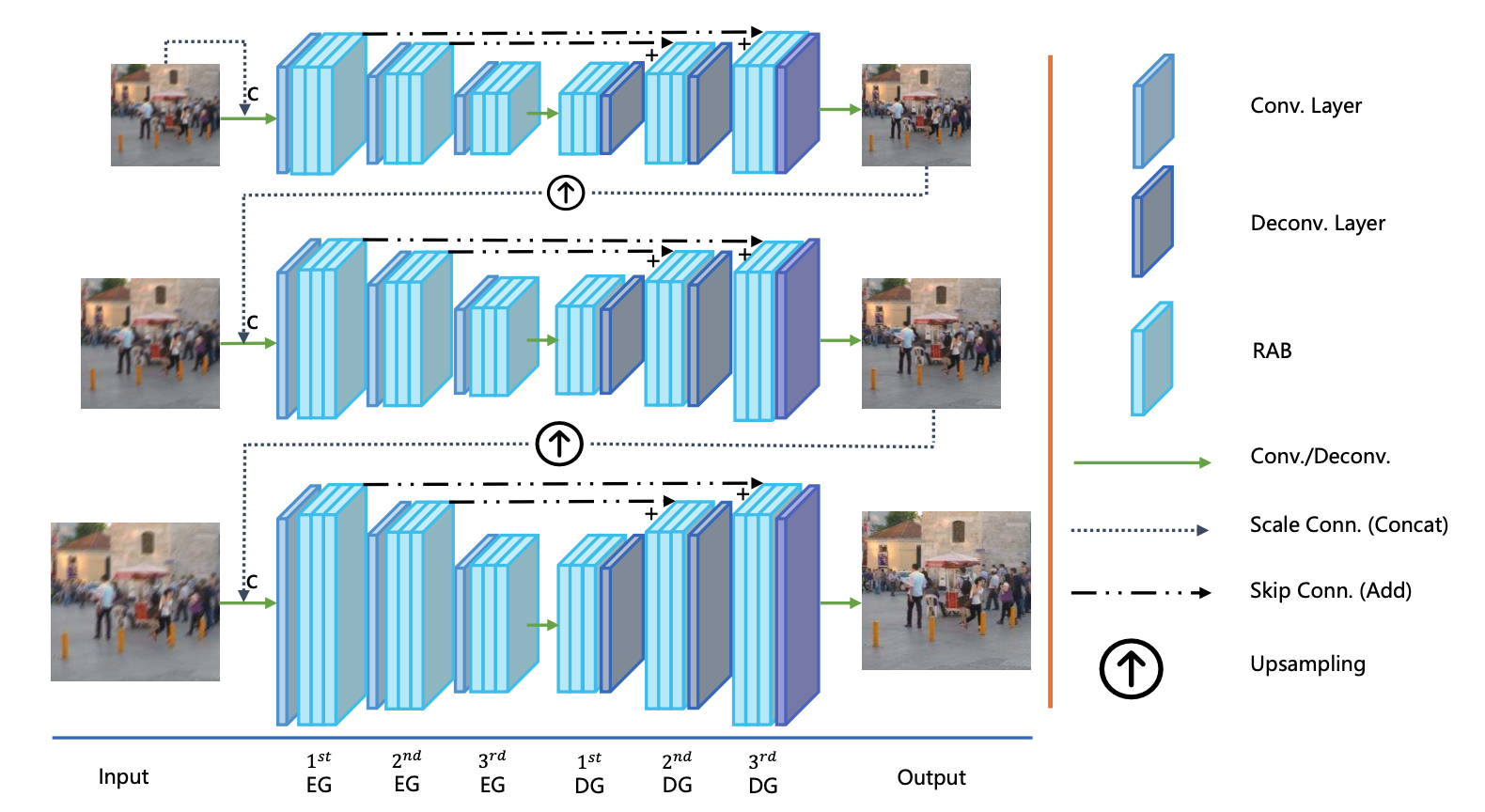
Attentive Deep Network for Blind Motion Deblurring on Dynamic Scenes
An attentive deep architecture for blind motion deblurring in dynamic scenes.

Enforcing Temporal Consistency in Video Depth Estimation
Temporal consistency constraints for stable and accurate video depth estimation.